

SSU · Social Scene Understanding
Ground visible cues: action, expression, environment, attributes.
arXiv 2506.05425
1Peking University · 2State Key Lab of General AI, BIGAI · 3Tsinghua University · 4ShanghaiTech University
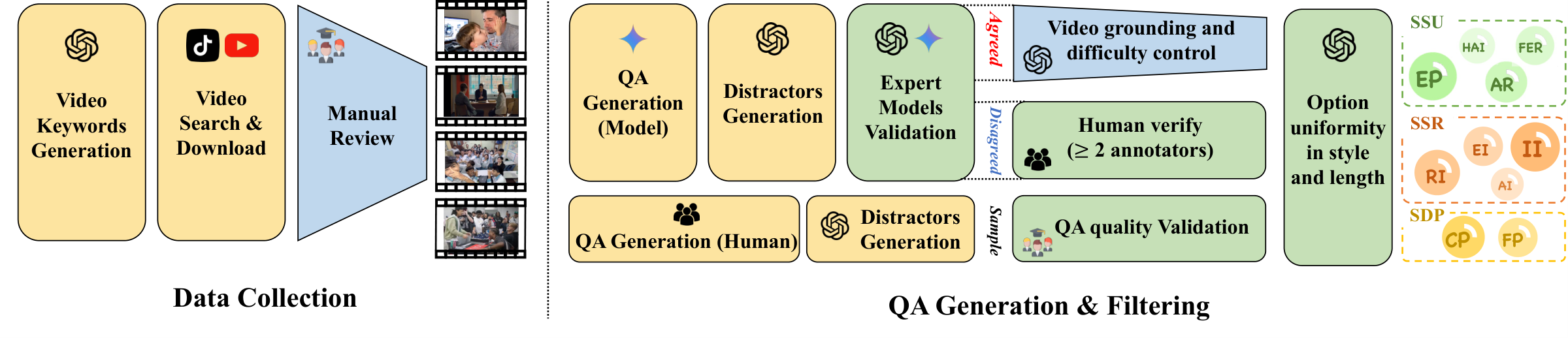
SIV-Bench evaluates how well multimodal language models understand real-world social interaction. Built on 2,792 curated video clips and 5,455 human-verified question–answer pairs, the benchmark spans three dimensions — perceiving what is visibly happening, inferring the latent social and mental state, and predicting how interactions will unfold — grounded in Fiske's relational models theory.

SSU · Social Scene Understanding
Ground visible cues: action, expression, environment, attributes.
SSR · Social State Reasoning
Infer latent signals: emotion, intent, attitude, relation.
SDP · Social Dynamics Prediction
Predict how interactions unfold, factually and counterfactually.
Source clips are mined from TikTok and YouTube, paired with QA generated by an LLM, then refined through adversarial filtering and human verification. Each video is evaluated under three subtitle conditions to isolate visual, auditory, and textual grounding.
Accuracy (%) on SSU, SSR, SDP, and the overall benchmark, under origin / +subtitle / −subtitle settings. Strong perception, but a consistent gap on social reasoning.
| Model | Params | SSU | SSR | SDP | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| orig | +sub | −sub | orig | +sub | −sub | orig | +sub | −sub | orig | +sub | −sub | ||
| Open-source MLLMs | |||||||||||||
| mPLUG-Owl3 | 7B | 46.11 | 45.94 | 46.34 | 39.78 | 39.50 | 38.13 | 44.30 | 46.08 | 44.35 | 42.06 | 42.42 | 41.15 |
| LLaVA-OneVision | 7B | 39.20 | 39.41 | 40.08 | 41.95 | 43.65 | 38.66 | 43.79 | 44.51 | 39.42 | 41.97 | 43.04 | 39.42 |
| LLaVA-Video | 7B | 50.22 | 50.61 | 50.56 | 39.33 | 38.19 | 36.14 | 41.60 | 42.14 | 39.94 | 41.09 | 42.00 | 38.66 |
| Qwen2.5-VL-7B-Instruct | 7B | 51.22 | 50.88 | 50.22 | 40.24 | 38.94 | 37.66 | 42.69 | 43.82 | 42.24 | 44.02 | 44.21 | 41.65 |
| InternVL3-8B | 8B | 56.83 | 56.13 | 56.50 | 40.35 | 40.90 | 37.92 | 44.53 | 45.52 | 44.40 | 45.82 | 46.05 | 44.56 |
| Qwen2.5-VL-72B-Instruct | 72B | 75.73 | 76.24 | 73.54 | 52.25 | 52.75 | 51.21 | 59.02 | 58.40 | 57.78 | 58.80 | 59.63 | 57.66 |
| InternVL3-78B | 78B | 71.46 | 73.66 | 71.76 | 51.65 | 52.39 | 50.14 | 55.77 | 56.28 | 54.25 | 55.46 | 56.32 | 54.50 |
| Closed-source MLLMs | |||||||||||||
| o4-mini | — | 78.83 | 79.04 | 78.13 | 50.47 | 51.30 | 48.99 | 56.89 | 56.00 | 55.26 | 55.68 | 55.89 | 54.54 |
| GPT-4o | — | 79.10 | 79.74 | 78.06 | 52.73 | 53.20 | 51.79 | 59.02 | 60.59 | 58.60 | 58.02 | 58.86 | 56.99 |
| Gemini-2.0-Flash | — | 78.46 | 78.16 | 78.34 | 51.89 | 52.43 | 49.78 | 57.59 | 58.63 | 55.70 | 56.40 | 57.23 | 54.64 |
| Gemini-2.5-Flash | — | 81.70 | 82.14 | 79.71 | 48.99 | 50.54 | 47.60 | 59.47 | 59.95 | 56.88 | 57.87 | 58.11 | 56.05 |
| Gemini-2.5-Pro | — | 85.07 | 85.41 | 84.94 | 54.30 | 54.85 | 52.32 | 60.45 | 61.54 | 58.83 | 61.65 | 62.40 | 60.22 |
Best overall: Gemini-2.5-Pro at 62.40% (+sub). Best open-source: Qwen2.5-VL-72B at 59.63% (+sub). Removing subtitles costs more on SSR (−2.07) and SDP (−1.68) than on SSU (−0.97), suggesting models lean on text more for higher-level reasoning.
A focused subset isolates the most failure-prone questions and adds short rationales, so we can compare both answer accuracy and reasoning quality against a human baseline.
| Model | Acc% | Relevance | Alignment | Coherence | Depth | Conciseness | Overall |
|---|---|---|---|---|---|---|---|
| Reference | |||||||
| Human (n=3) | 74.40 | — | — | — | — | — | — |
| Models | |||||||
| Gemini-3-Pro | 45.50 | 4.66 | 3.30 | 4.67 | 3.49 | 4.87 | 4.10 |
| GPT-5.1 | 39.00 | 4.58 | 3.29 | 4.65 | 3.26 | 4.88 | 4.00 |
| Gemini-2.5-Pro | 37.00 | 4.57 | 3.26 | 4.65 | 3.41 | 4.89 | 4.05 |
| Gemini-2.5-Flash | 32.32 | 4.48 | 3.17 | 4.55 | 3.22 | 4.87 | 3.95 |
| GPT-4o-mini | 29.00 | 4.45 | 3.20 | 4.56 | 3.12 | 4.91 | 3.90 |
| Qwen2.5-VL-7B | 24.50 | 4.00 | 2.89 | 4.21 | 3.05 | 4.45 | 3.63 |
The best model still trails the human baseline by ~29 points in answer accuracy. The gap is largest on alignment (how well the rationale fits social context) — where every model scores in the low-3 range against humans.
@misc{kong2025sivbench,
title = {SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning},
author = {Fanqi Kong and Weiqin Zu and Xinyu Chen and Yaodong Yang and Song-Chun Zhu and Xue Feng},
year = {2025},
eprint = {2506.05425},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2506.05425}
}