 Paper
Paper
 Code
Code
Welcome to SIV-Bench
Human social interaction is rich and multifaceted. SIV-Bench is a novel video benchmark designed to rigorously evaluate how well Multimodal Large Language Models (MLLMs) comprehend these complex social dynamics. We assess capabilities across scene understanding, state reasoning, and dynamics prediction.

Figure 1: SIV-Bench overview: Illustrating video diversity by social relationship models and sample QAs for Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamics Prediction (SDP).
Our Analytical Framework
SIV-Bench evaluates MLLMs across three core, interrelated dimensions, grounded in the understanding that social relationships fundamentally shape interactions:
Social Scene Understanding (SSU)
Perceiving observable elements: actions, expressions, environment, and attributes.
Social State Reasoning (SSR)
Inferring unobservable mental states: emotions, intentions, attitudes, and relationships.
Social Dynamics Prediction (SDP)
Anticipating how interactions evolve or would change under alternative (counterfactual) conditions.
The SIV-Bench Dataset
Our dataset comprises 2,792 real-world video clips representing 14 distinct social relationship types (grounded in Fiske's Relational Models Theory). It features diverse genres, presentation styles, and linguistic/cultural backgrounds, with 8,792 high-quality QAs from a human-LLM pipeline. Videos are presented under three subtitle conditions (`origin`, `+sub`, `-sub`) to test textual cue impact.
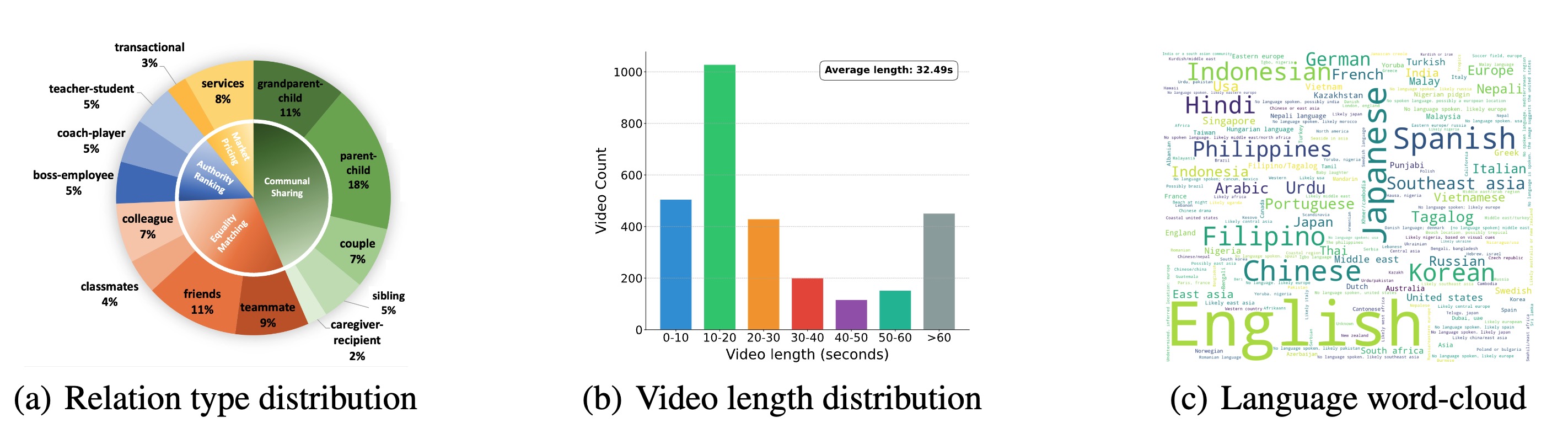
Video Statistics: Illustrating diversity in (a) social relation types, (b) video lengths (avg. 32.49s), and (c) represented languages.
The construction of SIV-Bench follows a meticulous pipeline, encompassing initial data collection through keyword-driven video sourcing and manual review, followed by a comprehensive QA generation and filtering process leveraging both LLM automation and human oversight.
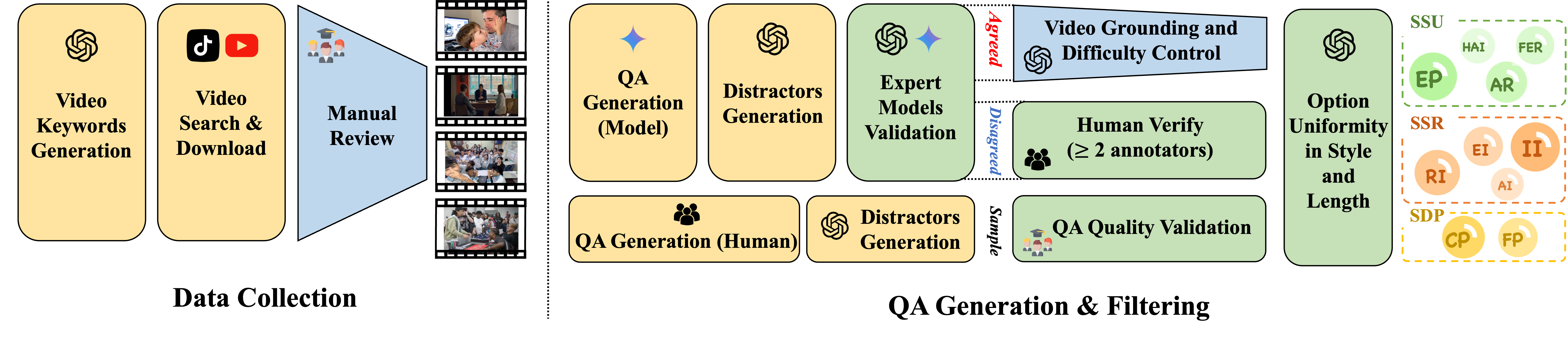
Construction Pipeline: SIV-Bench construction pipeline, detailing data collection process (left), and QA generation & filtering (right).
Key Experimental Results
We evaluated leading MLLMs using VLMEvalKit. Key findings highlight current strengths and areas for improvement in social AI:
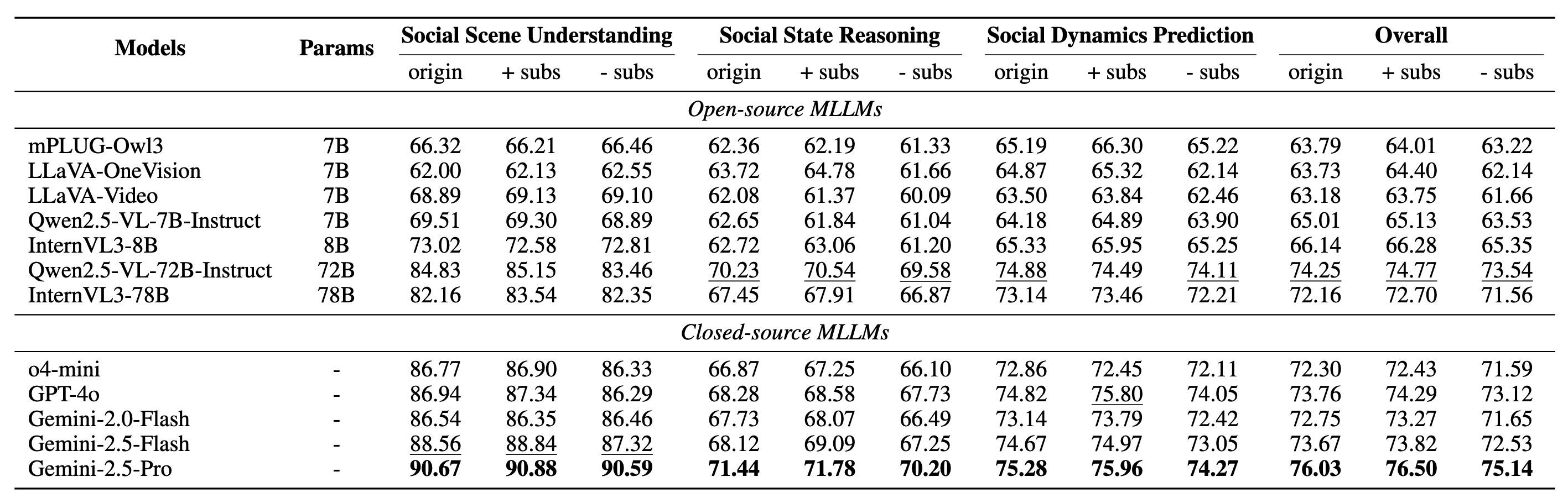
Main Results Table: MLLM accuracy (%) on SSU, SSR, SDP, and Overall scores across three subtitle conditions.
Models generally excel at SSU but significantly struggle with SSR, especially Relation Inference. Top models show notable strength in SDP's counterfactual reasoning. Transcribed subtitles (`+sub`) consistently aid comprehension of complex inferences, while their removal (`-sub`) typically hinders performance.
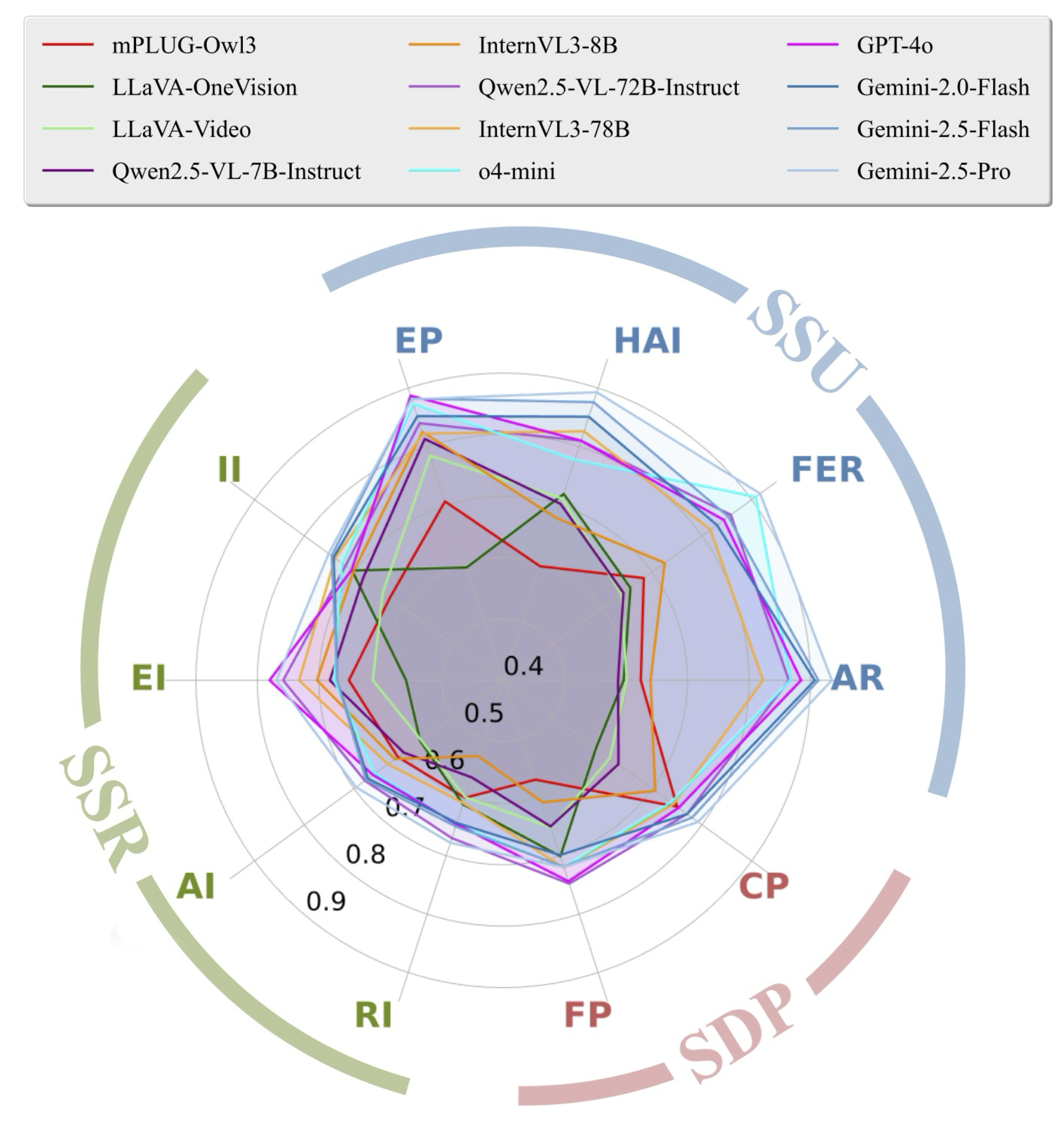
Fine-grained Performance: MLLM capabilities vary across our 10 detailed social understanding sub-tasks.
Citation
If you use SIV-Bench in your research, please cite our paper:
@misc{kong2025sivbenchvideobenchmarksocial,
title={SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning},
author={Fanqi Kong and Weiqin Zu and Xinyu Chen and Yaodong Yang and Song-Chun Zhu and Xue Feng},
year={2025},
eprint={2506.05425},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05425},
}